.webp "img")

Introduction
In 2024, scraping data from e-commerce platforms like Temu.com comes with unique challenges. Temu.com, a growing global e-commerce platform, offers a treasure trove of product data. From price information to product listings, reviews, and inventory data, the ability to scrape Temu.com data can provide valuable business insights. Extracting Temu.com data effectively can give companies a competitive edge in understanding market trends and consumer preferences. However, Temu.com data collection comes with complexities such as legal considerations, technical barriers, and managing large datasets, making it essential to address these challenges before diving into the process.
This blog will discuss the key challenges you might face while attempting to scrape Temu.com data and how you can overcome them.
1. Legal and Ethical Considerations
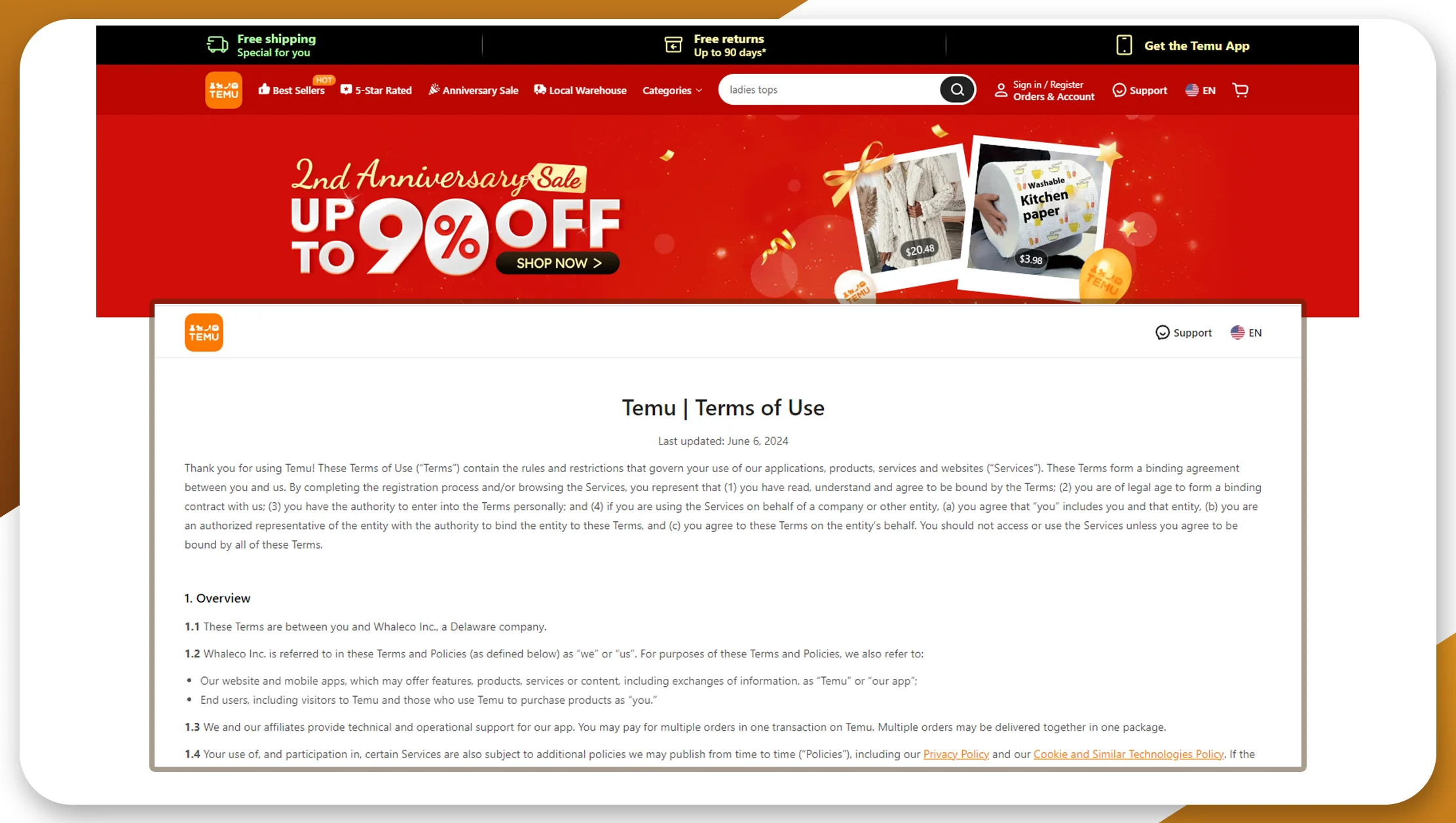
Legal challenges are one of the most critical issues to address when scraping Temu.com data. Many websites, including Temu.com, have terms of service that explicitly prohibit data extraction without permission. Engaging in unauthorized data scraping could lead to lawsuits, fines, or permanent blockage from accessing the website. Ensuring compliance with these regulations is crucial to avoid legal consequences while benefiting from Temu.com product data.
Some critical legal and ethical considerations include:
Terms of Service Violations: Scraping Temu.com product data without adhering to their guidelines can violate their terms of service.
Data Privacy: If you scrap Temu.com product reviews that include user data, you must ensure you aren’t violating privacy regulations like GDPR or CCPA.
Ethical Concerns: Ethical challenges revolve around fair use of the scraped data. Using Temu.com datasets for malicious purposes, such as spamming or reselling unauthorized data, is unethical.
Solution:
Review Temu.com’s data policies to stay compliant, and consider using the Temu API (if available) or getting explicit permission to scrape data. Tools emphasizing ethical scraping practices or allowing for targeted, respectful scraping can also help.
2. CAPTCHAs and Anti-Scraping Mechanisms
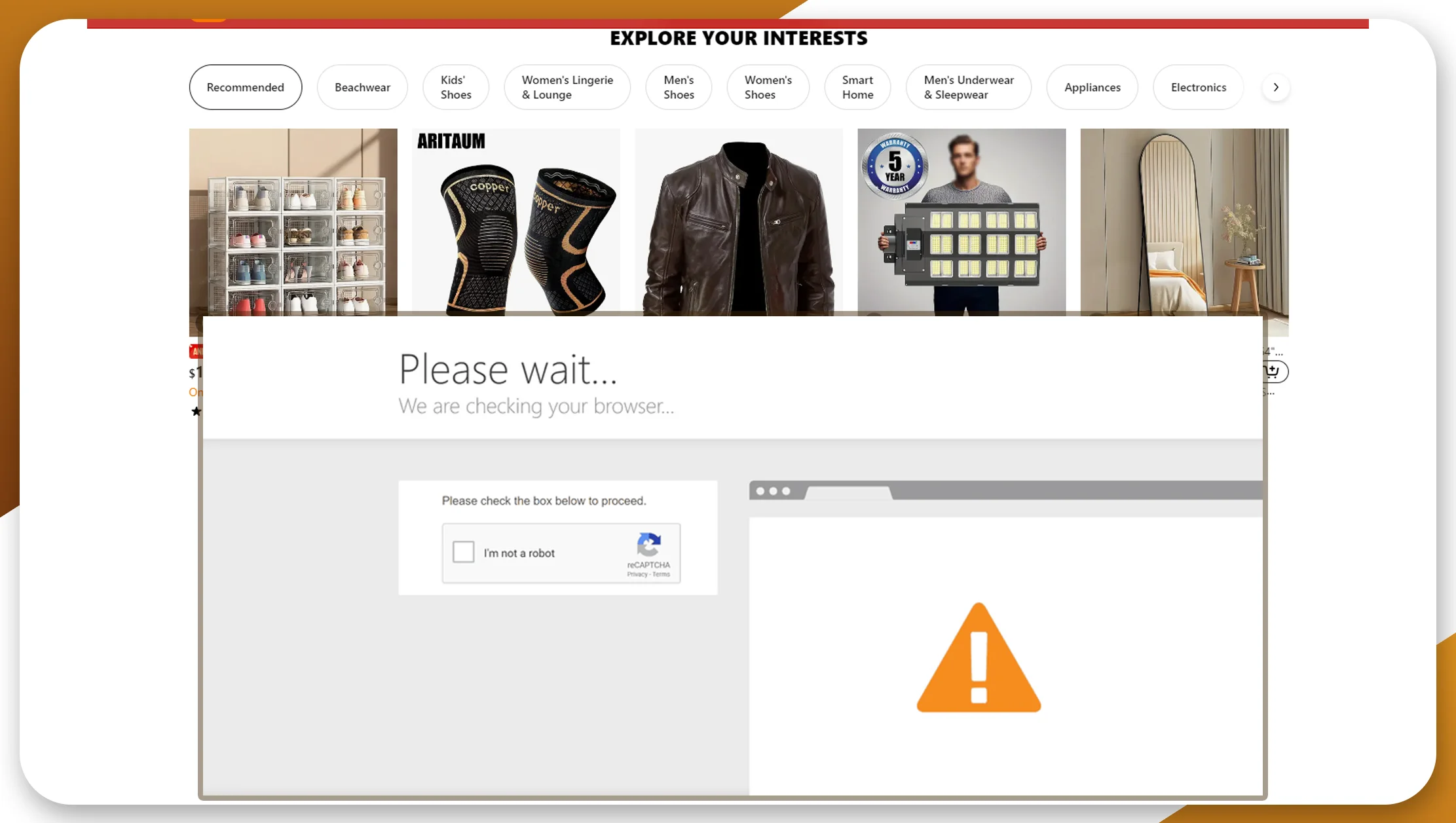
Advanced anti-bot measures can thwart Temu.com data scraping efforts. Websites often use CAPTCHAs to block automated scraping tools from accessing their content. Temu.com may deploy a mix of CAPTCHA challenges and rate-limiting strategies to prevent excessive requests from a single IP address.
Some challenges include:
IP Blocking: Frequent requests may lead to IP bans, cutting off your access to Temu.com datasets.
CAPTCHA Solvers: Captchas can make performing real-time product data scraping from Temu.com difficult.
Solution:
Rotating proxies or services that automatically solve CAPTCHAs can help overcome these challenges. Additionally, managing the frequency of requests and rotating user agents can reduce the likelihood of getting blocked.
3. Dynamic Content and JavaScript Rendering
Websites like Temu.com often use JavaScript to load product data dynamically, meaning traditional scraping methods won’t be able to capture content loaded asynchronously. This poses a significant challenge for extracting data such as product details from Temu.com and product price scraping from Temu.com.
Dynamically Loaded Product Listings: Product pages may load only a few times, making scraping Temu.com for product insights challenging.
Hidden Data: Key information like inventory data or product reviews might only appear after specific interactions, such as scrolling or clicking, which requires additional handling.
Solution:
Headless browsers or tools like Selenium and Puppeteer can render JavaScript and extract dynamic content. These tools allow you to fully load a webpage and ensure that you’re scraping product listing data accurately.
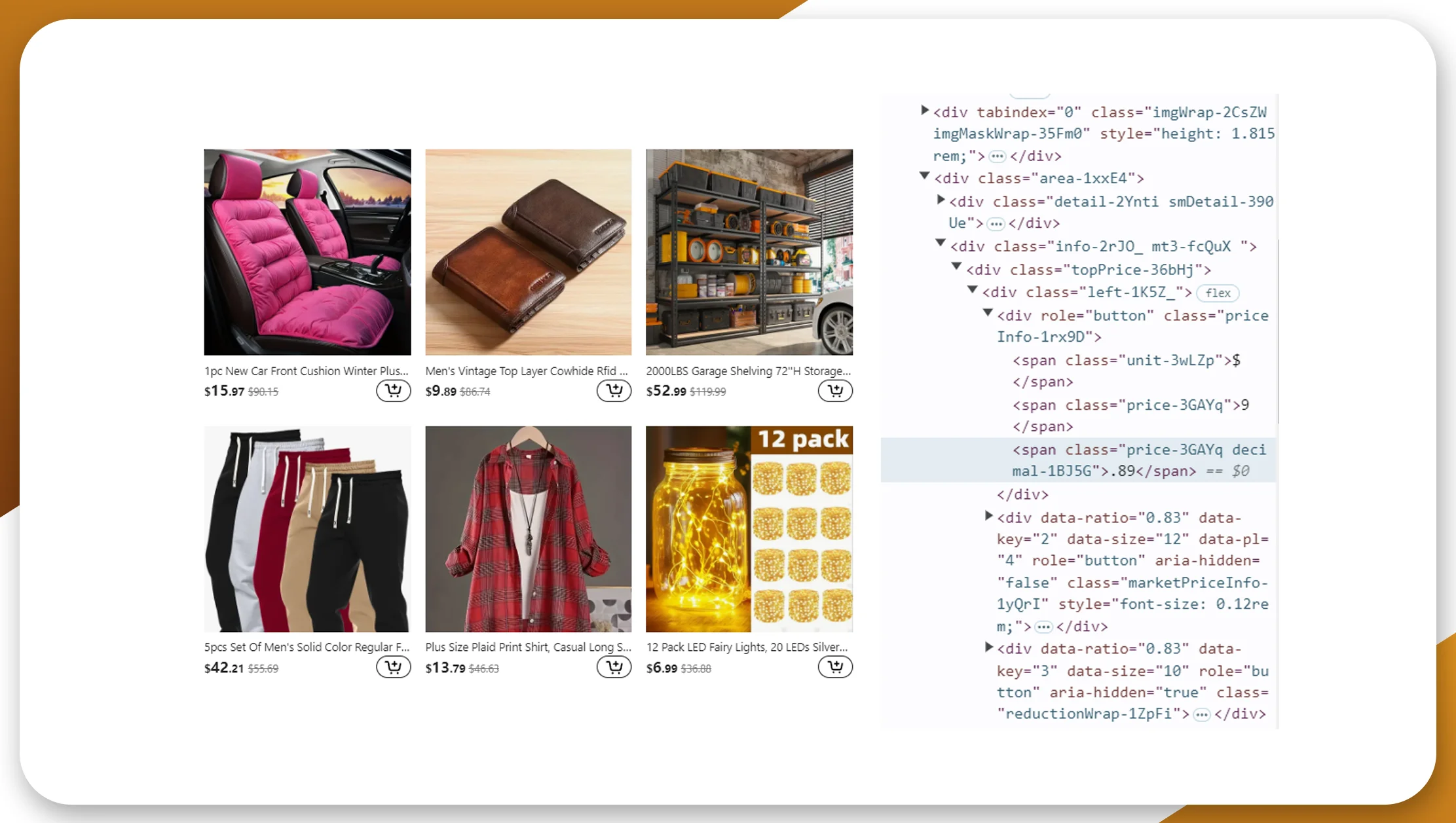
4. Complex Data Structures
E-commerce websites often present their data in complex, nested structures that are not easily accessible. Inconsistent product categories, varied review formats, and changing price and inventory data structures can hinder Temu.com product data scraping.
Some potential challenges include:
Nested Data Elements: Key product details like price, ratings, or stock levels may be embedded within multiple layers of HTML, making them harder to extract.
Non-Standardized Formats: Scraping product descriptions from Temu.com and reviews may require parsing different formats for each type of product or listing.
Solution:
To tackle this, advanced parsing methods and customized scrapers can help manage the complex structure. Libraries such as BeautifulSoup or Scrapy can extract Temu.com product listing data even from intricate, nested HTML structures.
5. Data Volume and Real-Time Scraping
Another major challenge is handling large volumes of data. Ecommerce product data scraping often requires collecting vast amounts of information from different product listings, reviews, and price points. Additionally, keeping this data updated in real-time presents hurdles.
Key challenges include:
Scalability: Extracting large datasets, such as Temu.com product reviews scraping or inventory data scraping, can overwhelm essential scraping tools.
Real-Time Updates: Real-time product data scraping from Temu.com is complex because product information like price and stock levels change frequently.
Solution:
To manage large datasets and maintain up-to-date information, consider cloud-based scraping solutions that allow for scalability. The Temu API (if available) is the most reliable for real-time scraping, or a combination of scheduling tools and fast scraping scripts can help.
6. Content Duplication and Quality
When scraping product data from Temu.com, content duplication and ensuring data quality can be severe. For instance, product descriptions may be duplicated across multiple pages, or you might inadvertently scrape outdated prices. These challenges can compromise the accuracy and usefulness of the data collected, making it essential to implement processes to filter out duplicates and maintain high-quality, up-to-date information during Temu.com data collection.
Key issues:
Duplicate Data: Duplicated product listings, descriptions, or reviews can lead to inaccurate analysis.
Data Quality: Scraping inconsistent data, like outdated product prices or irrelevant reviews, hampers the utility of your Temu.com data collection.
Solution:
To prevent duplication, you can implement deduplication processes within your scraper. Using database solutions to store your Temu.com datasets and compare them with incoming data helps maintain accuracy and integrity.
Conclusion
Scraping data from e-commerce platforms like Temu.com in 2024 has technical and ethical challenges. From anti-scraping measures such as CAPTCHAs and dynamic content to navigating legal concerns and complex data structures, extracting product details from Temu.com for valuable insights requires advanced strategies. Successfully scraping Temu.com for product insights demands careful planning to overcome these obstacles while ensuring data quality and compliance with legal frameworks.
For businesses aiming to extract valuable Temu.com datasets, investing in the right tools and ensuring you stay compliant with legal and ethical guidelines is essential. Tools that support ecommerce data scraping at scale while overcoming challenges like real-time updates and content duplication will ultimately provide the most reliable and actionable insights.
By addressing these challenges, you can turn Temu.com product data scraping, including Temu.com inventory data scraping and Temu.com product listing data extraction, into a powerful tool for gaining competitive advantage and driving business growth. Unlock the potential of accurate, real-time data with Real Data API. Start your data journey today!
Remember to approach data scraping ethically, respect Wolt's terms of service, and stay informed about the latest industry trends to make the most of your data-driven strategies. For accurate and real-time insights, leverage a reliable unlock the potential of your business today!
Latest posts




Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.








Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : Real Data API only extracts publicly available data while maintaining a strict policy against collecting any personal or identity-related information.