

Introduction
Web scraping is a powerful tool for gathering valuable information from online sources, and it’s especially useful for industries like grocery delivery. By using an Amazon Fresh grocery data scraper, businesses can collect detailed data on product offerings, prices, availability, and customer reviews. This process, known as Amazon Fresh data scraping, involves extracting data from Amazon Fresh to perform market research, price comparison, and more. An effective Amazon Fresh grocery delivery data extractor can provide insights into market trends and competitive pricing, helping businesses stay ahead. Leveraging web scraping services and tools like instant data scrapers enables efficient and comprehensive Amazon Fresh grocery data collection, essential for strategic decision-making.
Why Scrape Amazon Fresh Grocery Delivery Data?
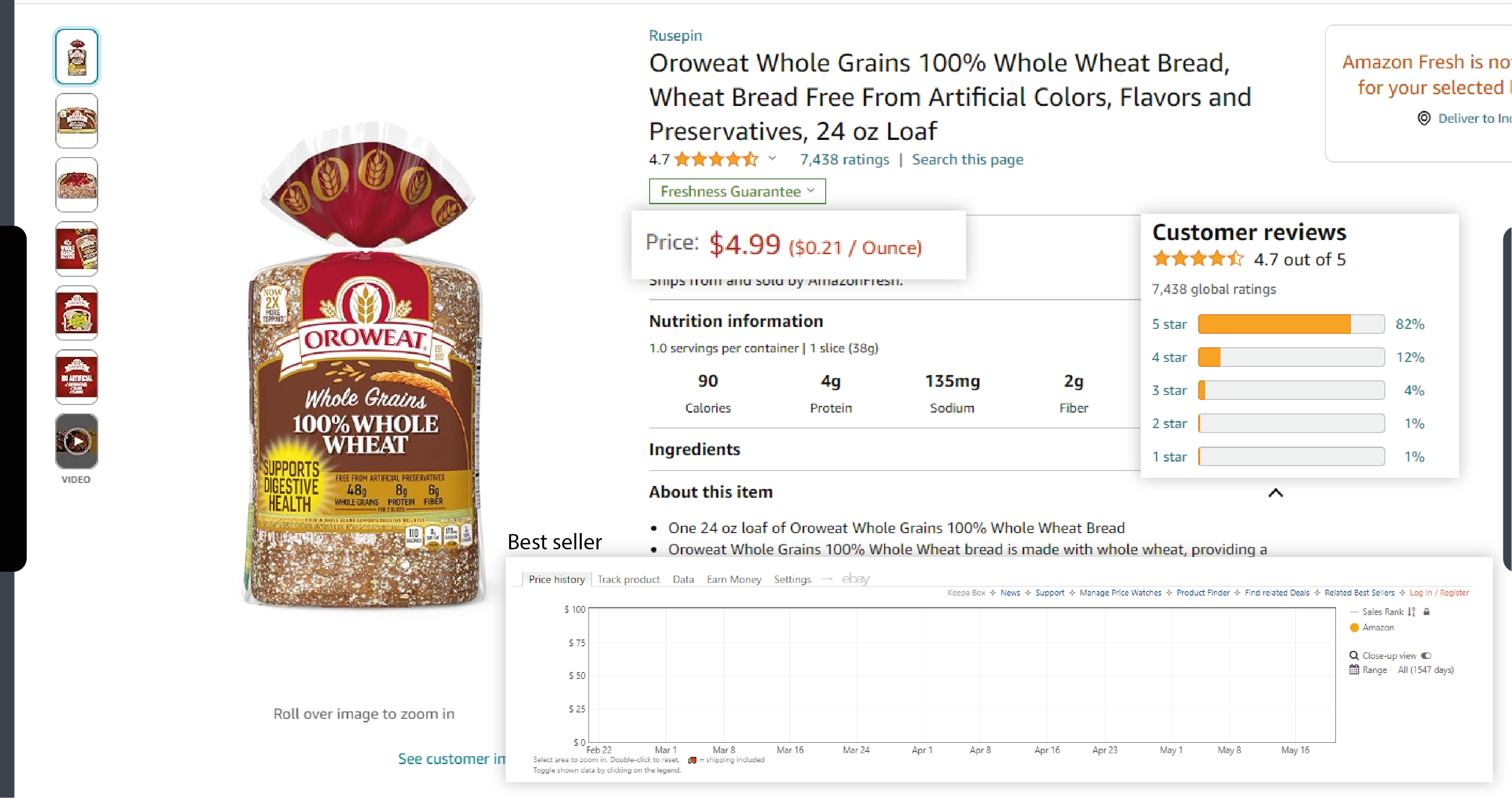
Amazon Fresh is a leading online grocery delivery service, offering a wide range of products from fresh produce to household essentials. When businesses extract data from Amazon Fresh, they can gain valuable insights into pricing trends, product availability, and customer preferences. Here are some key benefits:
Market Research: Understand market trends and consumer behavior.
Price Comparison: Monitor competitors' prices to adjust your pricing strategy.
Product Availability: Track stock levels to ensure product availability.
Customer Preferences: Analyze popular products and customer reviews to enhance your offerings.
Tools and Technologies for Amazon Fresh Data Scraping
Several tools and libraries can help you scrape Amazon Fresh grocery delivery data effectively:
BeautifulSoup: A Python library for parsing HTML and XML documents.
Scrapy: An open-source web crawling framework for Python.
Selenium: A tool for automating web browsers, often used for scraping dynamic content.
Puppeteer: A Node.js library that provides a high-level API to control Chrome or Chromium browsers.
Instant Data Scraper: A browser extension for quick and easy data extraction.
Steps to Scrape Amazon Fresh Grocery Delivery Data
Step 1: Identify Target Data
First, identify the data you want to scrape from Amazon Fresh. This could include product names, prices, availability, ratings, and reviews. Make a list of the URLs of the product pages you want to scrape.
Step 2: Inspect the Website Structure
Use your browser's developer tools to inspect the structure of the Amazon Fresh web pages. This will help you identify the HTML elements containing the data you need.
Step 3: Choose the Right Tool
Select the appropriate tool for your scraping needs. For this guide, we'll use BeautifulSoup and Selenium to handle both static and dynamic content.
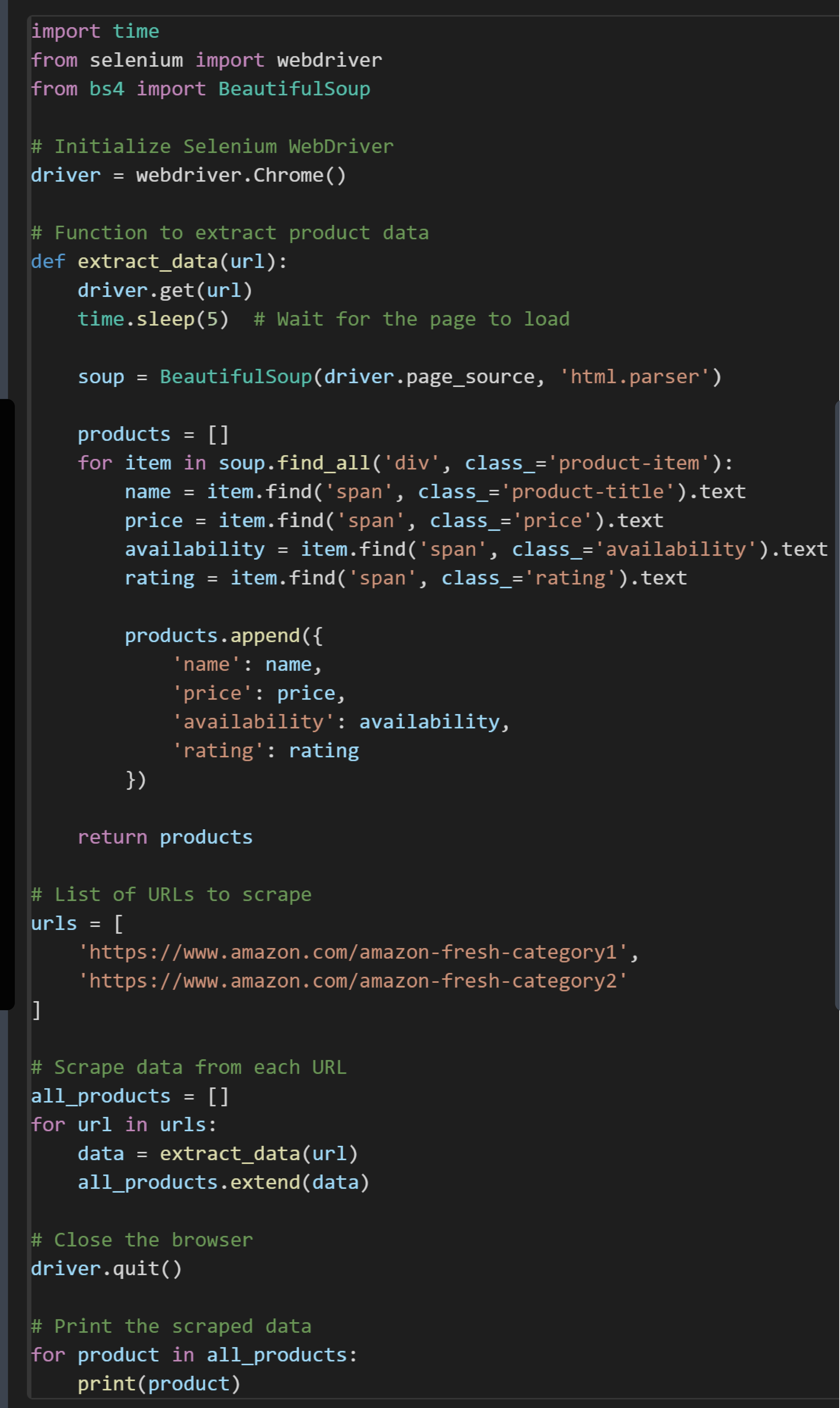
Step 4: Write the Scraping Script
Here is an example of how to write a script using BeautifulSoup and Selenium to scrape product data from Amazon Fresh:
Step 5: Handle Anti-Scraping Measures
Amazon Fresh, like many websites, implements anti-scraping measures such as CAPTCHAs and IP blocking. Here are some strategies to handle these:
Use Proxies: Rotate IP addresses using proxy servers to avoid detection.
Implement Rate Limiting: Add delays between requests to mimic human browsing behavior.
Solve CAPTCHAs: Use CAPTCHA solving services like 2Captcha to bypass CAPTCHA challenges.
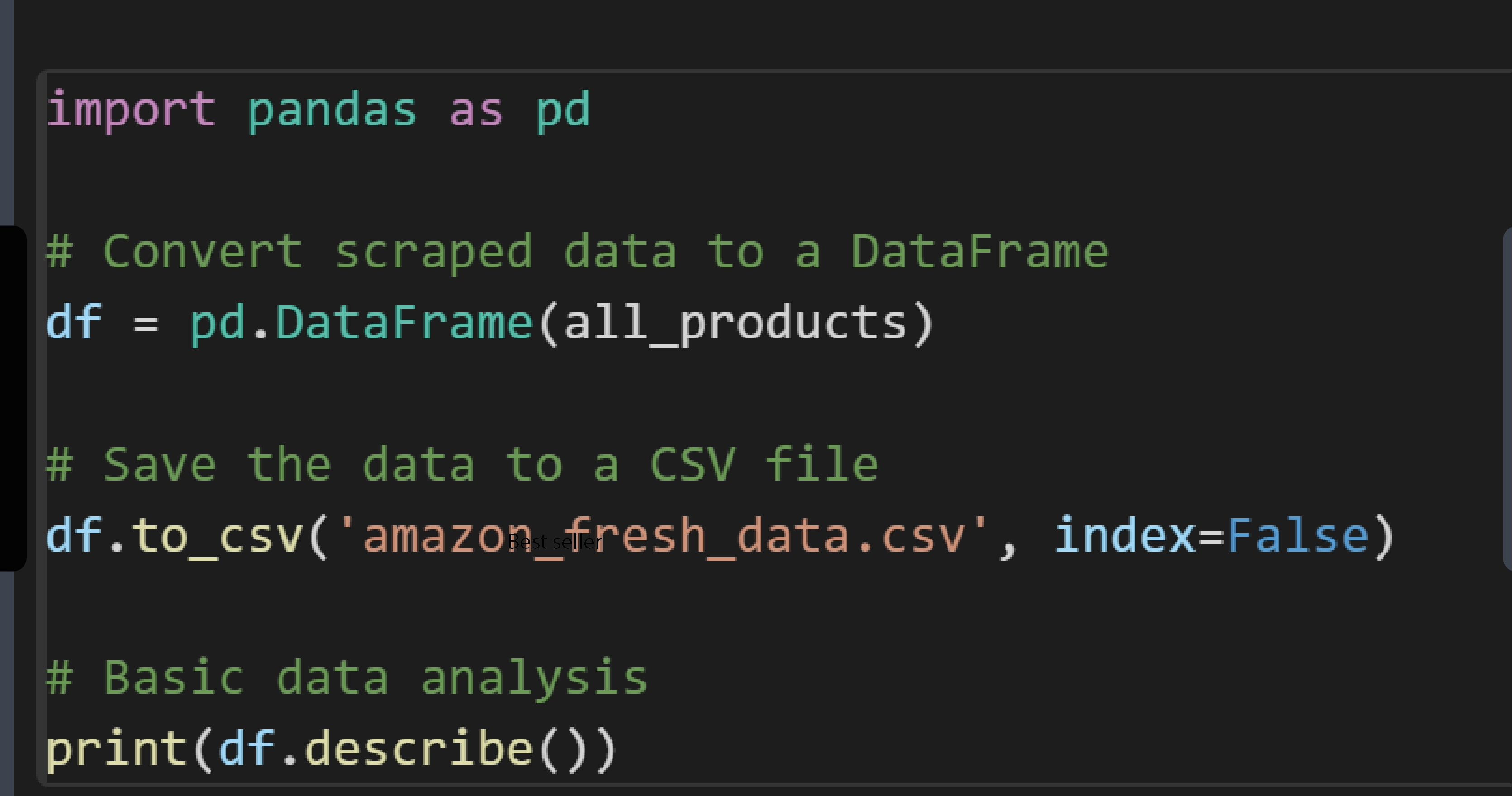
Step 6: Store and Analyze the Data
After scraping the data, store it in a structured format, such as a CSV file or a database. Use data analysis tools to derive insights from the collected data. For example, you can use pandas, a Python data analysis library, to analyze and visualize the data.
Benefits of Using Web Scraping Services
For businesses that prefer not to build their own scraping solutions, using web scraping services offers several benefits:
Ease of Use: These services provide ready-to-use solutions, reducing the need for in-house development.
Scalability: They can handle large volumes of data, making them suitable for businesses of all sizes.
Real-Time Data: Many services offer real-time data, ensuring that businesses always have the latest information.
Reduced Maintenance: Using a third-party service means you don’t have to worry about maintaining and updating your scraping scripts.
Future Trends in Web Scraping for the Grocery Industry
As technology evolves, the methods and applications of web scraping in the grocery industry are likely to expand. Here are some future trends to watch for:
AI and Machine Learning: Integrating AI and machine learning with web scraping can enhance data analysis, making it possible to uncover deeper insights and predictive analytics.
Blockchain Technology: Blockchain can provide more secure and transparent ways to gather and verify scraped data.
Advanced Automation: With advancements in automation, web scraping processes will become more efficient, reducing the need for manual intervention.
Enhanced Data Privacy: As data privacy regulations become more stringent, web scraping techniques will need to adapt to ensure compliance while still providing valuable data.
Conclusion
Web scraping is a key tool for the grocery delivery industry, providing essential data for strategic decision-making. Using an Amazon Fresh grocery data scraper, businesses can gather and analyze pricing, product availability, and customer reviews. This data is vital for market research, price comparison, and understanding customer preferences. It's important to follow best practices and comply with legal standards for ethical data collection. As the industry evolves, so will web scraping techniques and applications, offering more opportunities for innovation. Embrace web scraping with Real Data API for data solutions that drive success in the grocery delivery industry. Contact us today to get started!
Latest posts

How to Scrape Tourism Businesses in Japan to Track Travel Demand Trends and Boost Market Insights by 45%?

How Japan Travel Industry Data Extraction for Tourism Insights Can Help Hotels Reduce Seasonal Vacancies by 30%?

Solving Restaurant Competition Challenges Using Scraping Restaurant Menu Data In Tokyo For Competitive Insights And Boost Sales By 35%

How To Solve Price Fluctuation Challenges When Scrape Hotel And Flight Prices For Travel Data Analytics Japan?
Real Data API stands out as one of the premier global companies specializing in web data Scraping and web extraction.







Rating 4.7
Rating 4.7
Rating 4.5
Rating 4.7
Rating 4.7


Disclaimer : Real Data API only extracts publicly available data while maintaining a strict policy against collecting any personal or identity-related information.