What is Facebook Groups Scraper?
It is a robust data scraping tool that permits you to compile publicly available Facebook Groups data. You can get the required data by inserting the URL of the group page and clicking the Save and Start button.
What Kind of Data Can I Extract From Facebook Groups?
Using this Facebook data scraper API, you can collect data for the following Facebook data points.
- URL and post text
- Group URL
- Insights for likes and comments
- Basic information of commentator
- Timestamp
- Comment text
Why Scrape Data from Facebook Groups?
Crawling Facebook groups with public access can help you with automated data extraction and assist you in
- Perform market research
- Discover shifts in customer behavior
- Find hot spots of fake news, misinformation, and hate speech.
- Study social media phenomena with influence.
The process of using Facebook Groups Data Scraper
We've designed a simple Facebook Groups Scraper to start if you are just entering into data scraping. Check the below steps to scrape Facebook Groups using this API.
- Create a free Real Data API account using the necessary details, including email.
- Go to Facebook Groups Scraper.
- Add as many links to public Facebook groups as possible to scrape data.
- Tap the Start button and allow some time for the scraper to extract the data according to your needs.
- Export the collected data in multiple formats, including HTML, CSV, JSON, Excel, XML, etc.
If you want to learn about the process of using this scraper, check out our stepwise tutorial.
How Private and Public Facebook Groups Different from Each Other?
As the name suggests, a private Facebook group is invisible to everyone. A group admin manages it and approves new joining and posting. Whereas it is not the case with public Facebook groups. Anyone can join and post anything on the public group without permission from the admin.
Input Example for Facebook Groups Scraper
You should feed links of Publicly available Facebook groups in the input field of this scraper to scrape the data from groups. To check the complete description of the input example, visit the input tab and see the JSON example.
{
"persistCookiesPerSession": false,
"proxy": {
"useRealdataAPIProxy": true,
"RealdataAPIProxyGroups": [
"RESIDENTIAL"
]
},
"resultsLimit": 1000,
"startUrls": [
{
"url": "https://www.facebook.com/groups/germtheory.vs.terraintheory"
}
],
"useSessionPool": true,
"viewOption": "",
"maxRequestRetries": 10
}
...
Sample Output
You can check the dataset with wrapped output in the Storage tab. If you apply the above input parameters, you'll get the below sample output.
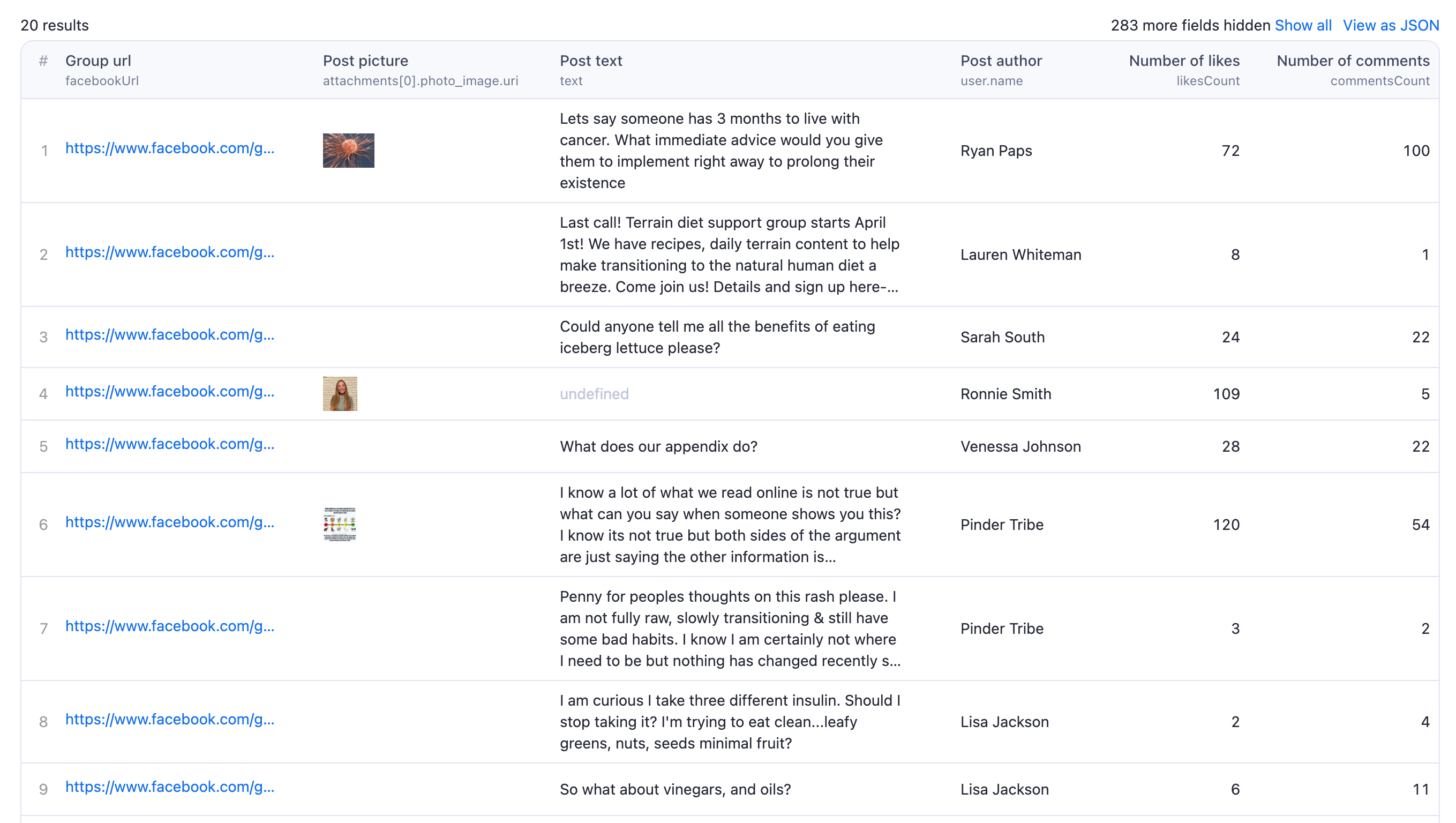
Additionally, check the JSON output here. You can choose the format in which you want the scraped data out HTML, XML, CSV, Excel, JSON, etc.
[
{
"facebookUrl": "https://www.facebook.com/groups/germtheory.vs.terraintheory",
"id": "UzpfSTEwMDAzOTAzNTk1NjYzNDpWSzo2MjY1OTkyNTE2ODExMDM3",
"feedbackId": "ZmVlZGJhY2s6NjI2NTk5MjUxNjgxMTAzNw==",
"user": {
"id": "pfbid0KXyYXC9nmsqUhrg2btvzvVRpNmUjdfriBFigztn7XNhE1hWVHzuigPX9nqpxu3u6l",
"name": "Ryan Paps",
"profileUrl": "https://www.facebook.com/ryan.paps.94",
"profilePic": "https://scontent-msp1-1.xx.fbcdn.net/v/t39.30808-1/227521685_528650028446191_6241547349257445408_n.jpg?stp=cp0_dst-jpg_p40x40&_nc_cat=105&ccb=1-7&_nc_sid=7206a8&_nc_ohc=4rKnQxOvOtoAX-l4ENT&_nc_ht=scontent-msp1-1.xx&oh=00_AfCkHM1vmLSZza_L0KEQHJcanCvo0bz7AENHHzXlHik2gQ&oe=64332818"
},
"date": "2023-03-23T13:51:14.000Z",
"url": "https://www.facebook.com/groups/germtheory.vs.terraintheory/posts/6265992516811037/",
"text": "Lets say someone has 3 months to live with cancer. What immediate advice would you give them to implement right away to prolong their existence",
"attachments": [
{
"__typename": "Photo",
"photo_image": {
"uri": "https://scontent-msp1-1.xx.fbcdn.net/v/t39.30808-6/337400651_588356273005165_4266624846195676380_n.jpg?stp=dst-jpg_p180x540&_nc_cat=104&ccb=1-7&_nc_sid=5cd70e&_nc_ohc=oWx0CT6rvxwAX-D_p1v&_nc_ht=scontent-msp1-1.xx&oh=00_AfDF-c31knpZbveCFrHzeFWQ7y7F36LlOHKf2ulqAEZb2w&oe=6433DA59",
"height": 540,
"width": 810
},
"__isMedia": "Photo",
"accent_color": "FF665254",
"photo_product_tags": [],
"url": "https://www.facebook.com/photo.php?fbid=916459069665283&set=gm.6265992516811037&type=3",
"id": "916459069665283",
"ocrText": "May be a closeup of flower"
}
],
"likesCount": 72,
"commentsCount": 100,
"comments": [
{
"id": "Y29tbWVudDo2MjY1OTkyNTE2ODExMDM3XzYzMDUyMDMzNTk1NTY2MTk=",
"feedbackId": "ZmVlZGJhY2s6NjI2NTk5MjUxNjgxMTAzN182MzA1MjAzMzU5NTU2NjE5",
"date": "2023-04-06T04:16:55.000Z",
"text": "Change your diet, but don’t believe that a diet alone is going to save your life. Explore other holistic options in the process.",
"profilePicture": "https://scontent-msp1-1.xx.fbcdn.net/v/t39.30808-1/328235070_1389922131784056_6443811810941213910_n.jpg?stp=c0.0.32.32a_cp0_dst-jpg_p32x32&_nc_cat=100&ccb=1-7&_nc_sid=7206a8&_nc_ohc=Zjum7_vSimEAX8kDpUN&_nc_ht=scontent-msp1-1.xx&oh=00_AfAIK9msGXBv2KyocehWtPbmVH2a-SZjxppwxbyU66OFnA&oe=6434432E",
"likesCount": 0
},
{
"id": "Y29tbWVudDo2MjY1OTkyNTE2ODExMDM3XzYzMDUwNzcyMjYyMzU4OTk=",
"feedbackId": "ZmVlZGJhY2s6NjI2NTk5MjUxNjgxMTAzN182MzA1MDc3MjI2MjM1ODk5",
"date": "2023-04-06T03:10:30.000Z",
"text": "I am sure that Syd Barnes could say a few things about that subject…",
"profilePicture": "https://scontent-msp1-1.xx.fbcdn.net/v/t39.30808-1/299287659_10223367875533870_5249827628604891044_n.jpg?stp=cp0_dst-jpg_p32x32&_nc_cat=107&ccb=1-7&_nc_sid=7206a8&_nc_ohc=nZW0GCg_IHwAX_GsxPu&_nc_ht=scontent-msp1-1.xx&oh=00_AfCSjPhB_RJYVsqaqBRbbnMpsJ44qrX1pmsQyjTysIjLdA&oe=643354A4",
"likesCount": 0
}
]
...
What is the Cost of Using Facebook Groups Scraper?
If you use this actor to scrape Facebook groups on the Real Data API platform, you should use residential proxy servers from our monthly personal plan of 49 USD.
To know more about platform credits, the working of our pricing, usage, and proxy servers, check the pricing page or watch the video tutorial.
Do You Wish to Extract Reviews or Photos From Facebook?
We have dedicated scrapers for multiple data fields if you want to extract specific data from Facebook. Be it comments, posts, photos, events, or reviews, we have scrapers for each; check the list below to explore them.
- Facebook Events Scraper
- Facebook Comments Scraper
- Facebook Reviews Scraper
- Facebook Pages Scraper
- Facebook Photos Scraper
- Facebook Posts Scraper
Facebook Groups Scraper with Real Data API Integrations
Lastly, you can connect Facebook Groups Scraper with any web application or cloud service using Real Data API integrations. You have multiple options to integrate Scraper, including Zapier, Asana, GitHub, Make, Airbyte, Slack, Google Drive, Google Sheets, and more.
Further, you can use Webhooks to carry out event occurrence actions, like getting an alert once the scraper completes the execution successfully.
Using Facebook Groups Data Scraper with Real Data API
The Real Data API platform gives you programmatic access to use scrapers. We have organized the Facebook Groups API around RESTful HTTP endpoints to allow you to schedule, manage, and execute it. It also allows you to monitor scraper performance, access datasets, update and create versions, retrieve outputs, and more. To use the scraper using Python, try out the client PyPl package, and to use it using Node.js, try our client NPM package. For complete details, check out the API tab and explore code examples.
Can I Scrape Facebook Groups Data Legally?
Scraping data with ethics is our topmost priority, with user privacy. Therefore our scrapers don't scrape private data like location, email ids, or gender. But, there may be a case with unwanted personal data in output sometimes. We recommend you not scrape any personal information without any genuine reason.
You can consult your lawyers for advice if you are unaware of whether you have a genuine reason.
Performance Feedback From Your Experience with Scraper
We always work to improve our scraper performances. Therefore, if you want to suggest something in the performance, improvement, or anything else you want to suggest, contact us, or create an issue using the Issue tab in the Real Data API console.















